开发者工具
开发者工具


 运营增长
运营增长
 数据洞察
数据洞察
 AI提效
AI提效

 通用解决方案
通用解决方案
 行业解决方案
行业解决方案








【干货精选】个推Elasticsearch集群中JVM问题的应对之策
- 大数据
- 系统架构
 发表于2015年12月10日
发表于2015年12月10日

作为最专业的推送技术服务商,在产品不断的迭代过程中,个推整体的搜索引擎框架也在随之不断优化,个推曾在使用Elasticsearch中曾遇到过一些问题,也希望在我们实际遇到的一些问题当中,通过和大家的分享能共同完善和优化Elasticsearch项目。
个推基于Elasticsearch搜索引擎架构演变
◆个推搜索引擎选型过程
个推的搜索引擎框架经历了不断变化不断优化的过程,从原先的solr的单点到后面的Elasticsearch集群,经历了从单点到集群的转变,而且在开源搜索引擎选型上经历了从原先的solr到开源的可扩展的Elasticsearch的选型的变化。当时我们在做solr和Elasticsearch对比测试的时候发现,Elasticsearch的性能、搜索性能,比solr要优越一些,所以现在整个个推的搜索系统都是基于Elasticsearch做的而且最重要一点它是开源的,因此我们可以根据个推自身的业务来针对Elasticsearch做一些自己的优化,包括一些自己业务的对源代码的处理之类。
◆个推Elasticsearch集群架构
目前个推的Elasticsearch集群,主要采用master-data和loadbalance的集群架构设计,后期个推的业务和搜索场景业务越来越复杂之后,我们要涉及到很多的聚合而且这种业务需求会越来越大,因此对数据的聚合操作各方面,在我们的集群里面单独设置了loadbalance节点,这个节点就是专门处理一些数据的聚合操作。
◆个推使用Elasticsearch历史演变过程以及遇到的问题和优化处理
个推从比较早就开始使用Elasticsearch,所以使用过程中无论从性能上还是各方面,都遇到了比较多的问题,首先我们建索引非常慢,当然这也是很多方面的一些原因,尤其Elasticsearch对整个硬件方面的性能要求其实还是挺高的。第二个问题,我们早期经常遇到节点脱离集群的问题,甚至有时候连master也会脱离集群。第三个是我们在使用1.2.2的Elasticsearch版本当中,发现get操作,经常会被堵塞。还有一个问题,我们在Elasticsearch的备份过程中遇到了一个到目前为止解决不是太好的问题,做索引备份和恢复的过程中,Elasticsearch备份无法恢复,但我们运行了两年多的时间不可能把所有Elasticsearch的备份都备份在这个集群上。目前个推采用的方式是我们备份这个Elasticsearch索引数据的时候,通过我们自己的自动化脚本,比如一个月备份之后,把它的目录做一个切换。当然我们自己也会做一些类似暴力测试或者什么样的,万一线上的集群挂了,能不能从备份里正常的恢复,我能不能在不停服务的情况下正常的保证所有的搜索功能是正常的。
个推具体分析Elasticsearch遇到的问题使用的工具
在我们Elasticsearch集群里,我们怎么使用JVM的分析工具,来分析实际使用Elasticsearch当中遇到的问题,如何通过JVM的分析来解决这些问题,包括后期的一些优化等。这里面大概列了五点,在我们的Elasticsearch集群里使用到了JVM工具,主要是gc的日志输出。还有jconsole的方式,出现问题的时候去分析内存,这些具体的信息。第三个是jvisualvm的方式,当我们的集群里面某个节点出现异常或者挂掉的时候,脱离集群的时候,通过我们的自动化脚本会自动的打一些关于这个节点的信息之类的。第四是jstack,最后一个会用到Eclipse的内存分析器,这些工具功能也非常强大,而且可视化包括一些具体的信息都可以展示的非常清楚,也有利于你去分析具体的问题。
个推Elasticsearch集群问题分析案例
在个推Elasticsearch实际使用过程中,我们遇到的相对来说比较典型或者有代表性的几个问题来跟大家简单的介绍一下,我们针对这些问题是如何去分析和解决这些问题的,包括我们后期的一些优化之类的。
◆节点脱离集群问题分析
[es-date-1224] [gc][young][3402090][244044] duration [887ms],collections [1]/[1.5s], total [887ms]/[3.3h], memory [4.5gb]->[4gb]/[6.9gb],all_pools {[young][499.4mb]->[782.8kb]/[532.5mb]}{[survivor][32.7mb]->[30.2mb]/[66.5mb]}{[old] [3.9gb]->[3.9gb]/[6.3gb]}
上面这个例子的情况无须紧张,只是young gc,并且只用了887ms,对于Elasticsear而言,没有啥影响。唯一需要留心的是,如果在日志中出现连续的和长时间的young gc则需要引起警觉,可能是你的Heap内存分配不够。
◆Elasticsearch集群index索引慢分析
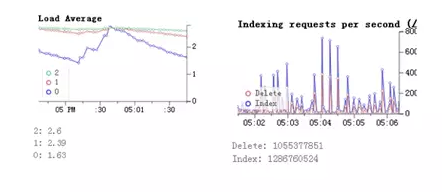
上图我们发现在这个节点上整个load并不是特别高,索引非常慢,而且并不是非常平稳。从客户端的jstack来看客户端实际上是堵塞的,最终导致整个的集群的索引性能上不去。早期的版本里,其实建索引,建flush,其实是有两个参数的,但早期其实默认配置是比较低的,后来我们把参数给调大,包括反射区的大小也进行了一个自己的超缩。通过这种方式,我们去解决Elasticsearch索引慢的情况。
◆Elasticsearch集群get操作慢分析
第三个问题,我们使用了Elasticsearch1.2.2这个版本之后,我们有很多业务需求是根据id去获取用户具体信息,通过get去获取索引内容,发现这个get请求并发量非常高而且每次的请求可能是通过不同的条件请求下,这个get的操作非常慢,而且我们从一些工具抓出来的信息可以看到,所有的机器基本上它的CPU都是跑满的,但我们可以看到在CPU跑满的情况下,其实其他的一些像gc、load都还是ok的,当时我们想什么样的操作导致我们的CPU基本上百分之百的状态下跑?我们当时通过对它的信息当时出问题的抓的情况下,具体的分析。因为每次get请求的操作,你的条件都是不一样的,在我们1.2.2Elasticsearch版本里,在Elasticsearch集群里的resultcaches里是找不到上一次的查询结果的,所以它每次都会调一个identityHashCode来计算一个hash值。然后放入weakldentityMap中,这些操作占用了绝大部分的CPU时间,导致整个操作非常慢。我们升级到1.5.2以后,很明显的get操作就比原来提升到一个数量级上了,所以目前使用的是1.5.2版本。
个推Elasticsearch集群JVM优化
我们目前使用的JDK是1.7版本,相对来说能给到很好的支持这个Elasticsearch系统,并把它默认的系统配置都进行了一个调整。还有在明确自己需求的情况下我们禁用了jdk7默认的垃圾回收,并把垃圾回收的阀值进行了一个调高,对应调整了cache超时的时间,每层的分段所设置的允许的数量,也相应的降低了这个也是我们在实际个推使用Elasticsearch的过程中,不断的一个调优的过程中去完善整个基于Elasticsearch搜索系统。


 热门推荐
热门推荐
 视频中心
视频中心
 关注我们
关注我们

每日互动官方微信号
公司动态、品牌活动

个推官方微信号
新品发布、官方资讯

个推技术实践
技术干货、前沿科技